It is always good to know factors that affects your search engine optimization tips especially when it comes from the Google themselves like Matt Cutts. So here I'm sharing with you a transcript posted by Eric Enge of
Stone Temple Consulting when he interviewed Matt Cutts recently.
Interview Transcript
Eric Enge: Let's talk a little bit about the concept of crawl budget. My understanding has been that Googlebot would come to do a website knowing how many pages is was going to take that day, and then it would leave once it was done with those pages.
Matt Cutts: I'll try to talk through some of the different things to bear in mind. The first thing is that there isn't really such thing as an indexation cap. A lot of people were thinking that a domain would only get a certain number of pages indexed, and that's not really the way that it works.
"... the number of pages that we crawl is roughly proportional to your PageRank"
There is also not a hard limit on our crawl. The best way to think about it is that the number of pages that we crawl is roughly proportional to your PageRank. So if you have a lot of incoming links on your root page, we'll definitely crawl that. Then your root page may link to other pages, and those will get PageRank and we'll crawl those as well. As you get deeper and deeper in your site, however, PageRank tends to decline.
Another way to think about it is that the low PageRank pages on your site are competing against a much larger pool of pages with the same or higher PageRank. There are a large number of pages on the web that have very little or close to zero PageRank. The pages that get linked to a lot tend to get discovered and crawled quite quickly. The lower PageRank pages are likely to be crawled not quite as often.
One thing that's interesting in terms of the notion of a crawl budget is that although there are no hard limits in the crawl itself, there is the concept of host load. The host load is essentially the maximum number of simultaneous connections that a particular web server can handle. Imagine you have a web server that can only have one bot at a time. This would only allow you to fetch one page at a time, and there would be a very, very low host load, whereas some sites like Facebook, or Twitter, might have a very high host load because they can take a lot of simultaneous connections.
Your site could be on a virtual host with a lot of other web sites on the same IP address. In theory, you can run into limits on how hard we will crawl your site. If we can only take two pages from a site at any given time, and we are only crawling over a certain period of time, that can then set some sort of upper bound on how many pages we are able to fetch from that host.
Eric Enge: So you have basically two factors. One is raw PageRank, that tentatively sets how much crawling is going to be done on your site. But host load can impact it as well.
Matt Cutts: That's correct. By far, the vast majority of sites are in the first realm, where PageRank plus other factors determines how deep we'll go within a site. It is possible that host load can impact a site as well, however. That leads into the topic of duplicate content. Imagine we crawl three pages from a site, and then we discover that the two other pages were duplicates of the third page. We'll drop two out of the three pages and keep only one, and that's why it looks like it has less good content. So we might tend to not crawl quite as much from that site.
If you happen to be host load limited, and you are in the range where we have a finite number of pages that we can fetch because of your web server, then the fact that you had duplicate content and we discarded those pages meant you missed an opportunity to have other pages with good, unique quality content show up in the index.
Eric Enge: That's always been classic advice that we've given people, that the one of the costs of duplicate content is wasted crawl budget.
Matt Cutts: Yes. One idea is that if you have a certain amount of PageRank, we are only willing to crawl so much from that site. But some of those pages might get discarded, which would sort of be a waste. It can also be in the host load realm, where we are unable to fetch so many pages.
Eric Enge: Another background concept we talk about is the notion of wasted link juice. I am going to use the term PageRank, but more generically I really mean link juice, which might relate to concepts like trust and authority beyond the original PageRank concept. When you link from one page to a duplicate page, you are squandering some of your PageRank, correct?
Matt Cutts: It can work out that way. Typically, duplicate content is not the largest factor on how many pages will be crawled, but it can be a factor. My overall advice is that it helps enormously if you can fix the site architecture upfront, because then you don't have to worry as much about duplicate content issues and all the corresponding things that come along with it. You can often use 301 Redirects for duplicate URLs to merge those together into one single URL. If you are not able to do a 301 Redirect, then you can fall back on rel=canonical.
Some people can't get access to their web server to generate a 301, maybe they are on a school account, a free host, or something like that. But if they are able to fix it in the site architecture, that's preferable to patching it up afterwards with a 301 or a rel=canonical.
Eric Enge: Right, that's definitely the gold standard. Let’s say you have a page that has ten other pages it links to. If three of those pages are actually duplicates which get discarded, have you then wasted three of your votes?
(
on duplicate content:) "What we try to do is merge pages, rather than dropping them completely"
Matt Cutts: Well, not necessarily. That's the sort of thing where people can run experiments. What we try to do is merge pages, rather than dropping them completely. If you link to three pages that are duplicates, a search engine might be able to realize that those three pages are duplicates and transfer the incoming link juice to those merged pages.
It doesn't necessarily have to be the case that PageRank is completely wasted. It depends on the search engine and the implementation. Given that every search engine might implement things differently, if you can do it on your site where all your links go to a single page, then that’s definitely preferable.
Eric Enge: Can you talk a little bit about Session IDs?
Matt Cutts: Don't use them. In this day and age, most people should have a pretty good idea of ways to make a site that don't require Session IDs. At this point, most software makers should be thinking about that, not just from a search engine point of view, but from a usability point of view as well. Users are more likely to click on links that look prettier, and they are more likely to remember URLs that look prettier.
If you can't avoid them, however, Google does now offer a tool to deal with Session IDs. People do still have the ability, which they’ve had in Yahoo! for a while, to say if a URL parameter should be ignored, is useless, or doesn't add value, they can rewrite it to the prettier URL. Google does offer that option, and it's nice that we do. Some other search engines do as well, but if you can get by without Session IDs, that's typically the best.
Eric Enge: Ultimately, there is a risk that it ends up being seen as duplicate content.
Matt Cutts: Yes, exactly, and search engines handle that well most of the time. The common cases are typically not a problem, but I have seen cases where multiple versions of pages would get indexed with different Session IDs. It’s always best to take care of it on your own site so you don't have to worry about how the search engines take care of it.
Eric Enge: Let's touch on affiliate programs. You are getting other people to send you traffic, and they put a parameter on the URL. You maintain the parameter throughout the whole visit to your site, which is fairly common. Is that something that search engines are pretty good at processing, or is there a real risk of perceived duplicate content there?
Matt Cutts: Duplicate content can happen. If you are operating something like a co-brand, where the only difference in the pages is a logo, then that's the sort of thing that users look at as essentially the same page. Search engines are typically pretty good about trying to merge those sorts of things together, but other scenarios certainly can cause duplicate content issues.
Eric Enge: There is some classic SEO advice out there, which says that what you really should do is let them put their parameter on their URL, but when users click on that link to get to your site, you 301 redirect them to the page without that parameter, and drop the parameter in a cookie.
Matt Cutts: People can do that. The same sort of thing that can also work for landing pages for ads, for example. You might consider making your affiliate landing pages ads in a separate URL directory, which you could then block in robots.txt, for example. Much like ads, affiliate links are typically intended for actual users, not for search engines. That way it’s very traceable, and you don't have to worry about affiliate codes getting leaked or causing duplicate content issues if those pages never get crawled in the first place.
Eric Enge: If Googlebot sees an affiliate link out there, does it treat that link as an endorsement or an ad?
(
on affiliate links:) "... we usually would not count those as an endorsement"
Matt Cutts: Typically, we want to handle those sorts of links appropriately. A lot of the time, that means that the link is essentially driving people for money, so we usually would not count those as an endorsement.
Eric Enge: Let's talk a bit about faceted navigation. For example, on Zappos, people can buy shoes by size, by color, by brand, and the same product is listed 20 different ways, so that can be very challenging. What are your thoughts on those kinds of scenarios?
Matt Cutts: Faceted navigation in general can be tricky. Some regular users don't always handle it well, and they get a little lost on where they are. There might be many ways to navigate through a piece of content, but you want each page of content to have a single URL if you can help it. There are many different ways to slice and dice data. If you can decide on your own what you think are the most important ways to get to a particular piece of content, then you can actually look at trying to have some sort of hierarchy in the URL parameters.
Category would be the first parameter, and price the second, for example. Even if someone is navigating via price, and then clicks on a category, you can make it so that that hierarchy of how you think things should be categorized is enforced in the URL parameters in terms of the position.
This way, the most important category is first, and the next most important is second. That sort of thing can help some search engines discover the content a little better, because they might be able to realize they will still get useful or similar content if they remove this last parameter. In general, faceted navigation is a tough problem, because you are creating a lot of different ways that someone can find a page. You might have a lot of intermediate paths before they get to the pay load.
If it's possible to keep things relatively shallow in terms of intermediate pages, that can be a good practice. If someone has to click through seven layers of faceted navigation to find a single product, they might lose their patience. It is also weird on the search engine side if we have to click through seven or eight layers of intermediate faceted navigation before we get to a product. In some sense, that's a lot of clicks, and a lot of PageRank that is used up on these intermediate pages with no specific products that people can buy. Each of those clicks is an opportunity for a small percentage of the PageRank to dissipate.
While faceted navigation can be good for some users, if you can decide on your own hierarchy how you would categorize the pages, and try to make sure that the faceted navigation is relatively shallow, those can both be good practices to help search engines discover the actual products a little better.
Eric Enge: If you have pages that have basically the same products, or substantially similar products with different sort orders, is that a good application for the canonical tag?
Matt Cutts: It can be, or you could imagine reordering the position of the parameters on your own. In general, the canonical tags idea is designed to allow you to tell search engines that two pages of content are essentially the same. You might not want to necessarily make a distinction between a black version of a product and a red version of a product if you have 11 different colors for that product. You might want to just have the one default product page, which would then be smart enough to have a dropdown or something like that. Showing minor variations within a product and having a rel=canonical to go on all of those is a fine way to use the rel=canonical tag.
Eric Enge: Let’s talk a little bit about the impact on PageRank, crawling and indexing of some of the basic tools out there. Let’s start with our favorite 301 Redirects.
Matt Cutts: Typically, the 301 Redirect would pass PageRank. It can be a very useful tool to migrate between pages on a site, or even migrate between sites. Lots of people use it, and it seems to work relatively well, as its effects go into place pretty quickly. I used it myself when I tried going from mattcutts.com to dullest.com, and that transition went perfectly well. My own testing has shown that it's been pretty successful. In fact, if you do site:dullest.com right now, I don't get any pages. All the pages have migrated from dullest.com over to mattcutts.com. At least for me, the 301 does work the way that I would expect it to. All the pages of interest make it over to the new site if you are doing a page by page migration, so it can be a powerful tool in your arsenal.
Eric Enge: Let’s say you move from one domain to another and you write yourself a nice little statement that basically instructs the search engine and, any user agent on how to remap from one domain to the other. In a scenario like this, is there some loss in PageRank that can take place simply because the user who originally implemented a link to the site didn't link to it on the new domain?
Matt Cutts: That's a good question, and I am not 100 percent sure about the answer. I can certainly see how there could be some loss of PageRank. I am not 100 percent sure whether the crawling and indexing team has implemented that sort of natural PageRank decay, so I will have to go and check on that specific case. (Note: in a follow on email, Matt confirmed that this is in fact the case. There is some loss of PR through a 301).
Eric Enge: Let’s briefly talk about 302 Redirects.
Matt Cutts: 302s are intended to be temporary. If you are only going to put something in place for a little amount of time, then 302s are perfectly appropriate to use. Typically, they wouldn't flow PageRank, but they can also be very useful. If a site is doing something for just a small amount of time, 302s can be a perfect case for that sort of situation.
Eric Enge: How about server side redirects that return no HTTP Status Code or a 200 Status Code?
Matt Cutts: If we just see the 200, we would assume that the content that was returned was at the URL address that we asked for. If your web server is doing some strange rewriting on the server side, we wouldn't know about it. All we would know is we try to request the old URL, we would get some content, and we would index that content. We would index it under the original URL’s location.
Eric Enge: So it’s essentially like a 302?
Matt Cutts: No, not really. You are essentially fiddling with things on the web server to return a different page's content for a page that we asked for. As far as we are concerned, we saw a link, we follow that link to this page and we asked for this page. You returned us content, and we indexed that content at that URL.
People can always do dynamic stuff on the server side. You could imagine a CMS that was implemented within the web server would not do 301s and 302s, but it would get pretty complex and it would be pretty error prone.
Eric Enge: Can you give a brief overview of the canonical tag?
Matt Cutts: There are a couple of things to remember here. If you can reduce your duplicate content using site architecture, that's preferable. The pages you combine don't have to be complete duplicates, but they really should be conceptual duplicates of the same product, or things that are closely related. People can now do cross-domain rel=canonical, which we announced last December.
For example, I could put up a rel=canonical for my old school account to point to my mattcutts.com. That can be a fine way to use rel=canonical if you can't get access to the web server to add redirects in any way. Most people, however, use it for duplicate content to make sure that the canonical version of a page gets indexed, rather than some other version of a page that you didn't want to get indexed.
Eric Enge: So if somebody links to a page that has a canonical tag on it, does it treat that essentially like a 301 to the canonical version of the page?
Matt Cutts: Yes, to call it a poor man's 301 is not a bad way to think about it. If your web server can do a 301 directly, you can just implement that, but if you don't have the ability to access the web server or it's too much trouble to setup a 301, then you can use a rel=canonical.
It’s totally fine for a page to link to itself with rel=canonical, and it's also totally fine, at least with Google, to have rel=canonical on every page on your site. People think it has to be used very sparingly, but that's not the case. We specifically asked ourselves about a situation where every page on the site has rel=canonical. As long as you take care in making those where they point to the correct pages, then that should be no problem at all.
Eric Enge: I think I've heard you say in the past that it’s a little strong to call a canonical tag a directive. You call it "a hint" essentially.
Matt Cutts: Yes. Typically, the crawl team wants to consider these things hints, and the vast majority of the time we'll take it on advisement and act on that. If you call it a directive, then you sort of feel an obligation to abide by that, but the crawling and indexing team wants to reserve the ultimate right to determine if the site owner is accidentally shooting themselves in the foot and not listen to the rel=canonical tag. The vast majority of the time, people should see the effects of the rel=canonical tag. If we can tell they probably didn't mean to do that, we may ignore it.
Eric Enge: The Webmaster Tools "ignore parameters" is effectively another way of doing the same thing as a canonical tag.
Matt Cutts: Yes, it's essentially like that. It’s nice because robots.txt can be a little bit blunt, because if you block a page from being crawled and we don't fetch it, we can't see it as a duplicative version of another page. But if you tell us in the webmaster console which parameters on URLs are not needed, then we can benefit from that.
Eric Enge: Let's talk a bit about KML files. Is it appropriate to put these pages in robots.txt to save crawl budget?
"... if you are trying to block something out from robots.txt, often times we'll still see that URL and keep a reference to it in our index. So it doesn't necessarily save your crawl budget"
Matt Cutts: Typically, I wouldn't recommend that. The best advice coming from the crawler and indexing team right now is to let Google crawl the pages on a site that you care about, and we will try to de-duplicate them. You can try to fix that in advance with good site architecture or 301s, but if you are trying to block something out from robots.txt, often times we'll still see that URL and keep a reference to it in our index. So it doesn't necessarily save your crawl budget. It is kind of interesting because Google will try to crawl lots of different pages, even with non-HTML extensions, and in fact, Google will crawl KML files as well. ,
What we would typically recommend is to just go ahead and let the Googlebot crawl those pages and then de-duplicate them on our end. Or, if you have the ability, you can use site architecture to fix any duplication issues in advance. If your site is 50 percent KML files or you have a disproportionately large number of fonts and you really don't want any of them crawled, you can certainly use robots.txt. Robots.txt does allow a wildcard within individual directives, so you can block them. For most sites that are typically almost all HTML with just a few additional pages or different additional file types, I would recommend letting Googlebot crawl those.
Eric Enge: You would avoid the machinations involved if it's a small percentage of the actual pages.
Matt Cutts: Right.
Eric Enge: Does Google do HEAD requests to determine the content type?
Matt Cutts: For people who don't know, there are different ways to try to fetch and check on content. If you do a GET, then you are requesting for the web server to return that content. If you do a HEAD request, then you are asking the web server whether that content has changed or not. The web server can just respond more or less with a yes or no, and it doesn't actually have to send the content. At first glance, you might think that the HEAD request is a great way for web search engines to crawl the web and only fetch the pages that have changed since the last time they crawled.
It turns out, however, most web servers end up doing almost as much work to figure out whether a page has changed or not when you do a HEAD request. In our tests, we found it's actually more efficient to go ahead and do a GET almost all the time, rather than running a HEAD against a particular page. There are some things that we will run a HEAD for. For example, our image crawl may use HEAD requests because images might be much, much larger in content than web pages.
In terms of crawling the web and text content and HTML, we'll typically just use a GET and not run a HEAD query first. We still use things like If-Modified-Since, where the web server can tell us if the page has changed or not. There are still smart ways that you can crawl the web, but HEAD requests have not actually saved that much bandwidth in terms of crawling HTML content, although we do use it for image content.
Eric Enge: And presumably you could use that with video content as well, correct?
Matt Cutts: Right, but I'd have to check on that.
Eric Enge: To expand on the faceted navigation discussion, we have worked on a site that has a very complex faceted navigation scheme. It's actually a good user experience. They have seen excellent increases in conversion after implementing this on their site. It has resulted in much better revenue per visitor which is a good signal.
Matt Cutts: Absolutely.
Eric Enge: On the other hand what they've seen is that the number of indexed pages has dropped significantly on the site. And presumably, it's because these various flavors of the pages which are for the most part just listing products in different orders essentially.
The pages are not text rich; there isn't a lot for their crawler to chew on, so that looks like poor quality pages or duplicates. What's the best way for someone like that to deal with this. Should they prevent crawling of those pages?
Matt Cutts: In some sense, faceted navigation can almost look like a bit of a maze to search engines, because you can have so many different ways of slicing and dicing the data. If search engines can't get through the maze to the actual products on the other side, then sometimes that can be tricky in terms of the algorithm determining the value add of individual pages.
Going back to some of the earlier advice I gave, one thing to think about is if you can limit the number of lenses or facets by which you can view the data that can be a little bit helpful and sometimes reduce confusion. That’s something you can certainly look at. If there is a default category, hierarchy, or way that you think is the most efficient or most user-friendly to navigate through, it may be worth trying.
You could imagine trying rel=canonical on those faceted navigation pages to pull you back to the standard way of going down through faceted navigation. That's the sort of thing where you probably want to try it as an experiment to see how well it worked. I could imagine that it could help unify a lot of those faceted pages down into one path to a lot of different products, but you would need to see how users would respond to that.
Eric Enge: So if Googlebot comes to a site and it sees 70 percent of the pages are being redirected or have rel=canonical to other pages, what happens? When you have a scenario like that, do you reduce the amount of time you spend crawling those pages because you've seen that tag there before?
Matt Cutts: It’s not so much that rel=canonical would affect that, but our algorithms are trying to crawl a site to ascertain the usefulness and value of those pages. If there are a large number of pages that we consider low value, then we might not crawl quite as many pages from that site, but that is independent of rel=canonical. That would happen with just the regular faceted navigation if all we see are links and more links.
It really is the sort of thing where individual sites might want to experiment with different approaches. I don't think that there is necessarily anything wrong with using rel=canonical to try to push the search engine towards a default path of navigating through the different facets or different categories. You are just trying to take this faceted experience and reduce the amount of multiplied paths and pull it back towards a more logical path structure.
Eric Enge: It does sound like there is a remaining downside here, that the crawler is going to spend a lot of it's time on these pages that aren't intended for indexing.
Matt Cutts: Yes, that’s true. If you think about it, every level or every different way that you can slice and dice that data is another dimension in which the crawler can crawl an entire product catalogue times that dimension number of pages, and those pages might not even have the actual product. You might still be navigating down through city, state, profession, color, price, or whatever. You really want to have most of your pages have actual products with lots of text on them. If your navigation is overly complex, there is less material for search engines to find and index and return in response to user's queries.
A lot of the time, faceted navigation can be like these layers in between the users or search engines, and the actual products. It’s just layers and layers of lots of different multiplicative pages that don't really get you straight to the content. That can be difficult from a search engine or user perspective sometimes.
Eric Enge: What about PageRank Sculpting? Should publishers consider using encoded Javascript redirects of links, or implementing links inside iframes?
Matt Cutts: My advice on that remains roughly the same as the advice on the original ideas of PageRank Sculpting. Even before we talked about how PageRank Sculpting was not the most efficient way to try to guide Googlebot around within a site, we said that PageRank Sculpting was not the best use of your time because that time could be better spent on getting more links to and creating better content on your site.
PageRank Sculpting is taking the PageRank that you already have and trying to guide it to different pages that you think will be more effective, and there are much better ways to do that. If you have a product that gives you great conversions and a fantastic profit margin, you can put that right at the root of your site front and center. A lot of PageRank will flow through that link to that particular product page.
Site architecture, how you make links and structure appear on a page in a way to get the most people to the products that you want them to see, is really a better way to approach it then trying to do individual sculpting of PageRank on links. If you can get your site architecture to focus PageRank on the most important pages or the pages that generate the best profit margins, that is a much better way of directly sculpting the PageRank then trying to use an iFrame or encoded JavaScript.
I feel like if you can get site architecture straight first, then you'll have less to do, or no need to even think about PageRank Sculpting. Just to go beyond that and be totally clear, people are welcome to do whatever they want on their own sites, but in my experience, PageRank Sculpting has not been the best use of peoples' time.
Eric Enge: I was just giving an example of a site with a faceted navigation problem, and as I mentioned, they were seeing a decline in the number of index pages. They just want to find a way to get Googlebot to not spend time on pages that they don't want getting in the index. What are your thoughts on this?
Matt Cutts: A good example might be to start with your ten best selling products, put those on the front page, and then on those product pages you could have links to your next ten or hundred best selling products. Each product could have ten links, and each of those ten links could point to ten other products that are selling relatively well. Think about sites like YouTube or Amazon; they do an amazing job of driving users to related pages and related products that they might want to buy anyway.
If you show up on one of those pages and you see something that looks really good, you click on that and then from there you see five more useful and related products. You are immediately driving both users and search engines straight to your important products rather than starting to dive into a deep faceted navigation. It is the sort of thing where sites should experiment and find out what works best for them.
There are ways to do your site architecture, rather than sculpting the PageRank, where you are getting products that you think will sell the best or are most important front and center. If those are above the fold things, people are very likely to click on them. You can distribute that PageRank very carefully between related products, and use related links straight to your product pages rather than into your navigation. I think there are ways to do that without necessarily going towards trying to sculpt PageRank.
Eric Enge: If someone did choose to do that (JavaScript encoded links or use an iFrame), would that be viewed as a spammy activity or just potentially a waste of their time?
"the original changes to NoFollow to make PageRank Sculpting less effective are at least partly motivated because the search quality people involved wanted to see the same or similar linkage for users as for search engines"
Matt Cutts: I am not sure that it would be viewed as a spammy activity, but the original changes to NoFollow to make PageRank Sculpting less effective are at least partly motivated because the search quality people involved wanted to see the same or similar linkage for users as for search engines. In general, I think you want your users to be going where the search engines go, and that you want the search engines to be going where the users go.
In some sense, I think PageRank Sculpting is trying to diverge from that. If you are thinking about taking that step, you should ask yourself why you are trying to diverge and send bots in a different location than users. In my experience, we typically want our bots to be seen on the same pages and basically traveling in the same direction as search engine users. I could imagine down the road if iFrames or weird JavaScript got to be so pervasive that it would affect the search quality experience, we might make changes on how PageRank would flow through those types of links.
It's not that we think of them as spammy necessarily, so much as we want the links and the pages that search engines find to be in the same neighborhood and of the same quality as the links and pages that users will find when they visit the site.
Eric Enge: What about PDF files?
Matt Cutts: We absolutely do process PDF files. I am not going to talk about whether links in PDF files pass PageRank. But, a good way to think about PDFs is that they are kind of like Flash in that they aren't a file format that's inherent and native to the web, but they can be very useful. In the same way that we try to find useful content within a Flash file, we try to find the useful content within a PDF file. At the same time, users don't always like being sent to a PDF. If you can make your content in a Web-Native format, such as pure HTML, that's often a little more useful to users than just a pure PDF file.
Eric Enge: There is the classic case of somebody making a document that they don't want to have edited, but they do want to allow people to distribute and use, such as an eBook.
Matt Cutts: I don't believe we can index password protected PDF files. Also, some PDF files are image based. There are, however, some situations in which we can actually run OCR on a PDF.
Eric Enge: What if you have a text-based PDF file rather than an image-based one?
Matt Cutts: People can certainly use that if they want to, but typically I think of PDF files as the last thing that people encounter, and users find it to be a little more work to open them. People need to be mindful of how that can affect the user experience.
Eric Enge: With the new JavaScript processing, what actually are you doing there? Are you actually executing JavaScript?
Matt Cutts: For a while, we were scanning within JavaScript, and we were looking for links. Google has gotten smarter about JavaScript and can execute some JavaScript. I wouldn't say that we execute all JavaScript, so there are some conditions in which we don't execute JavaScript. Certainly there are some common, well-known JavaScript things like Google Analytics, which you wouldn't even want to execute because you wouldn't want to try to generate phantom visits from Googlebot into your Google Analytics.
We do have the ability to execute a large fraction of JavaScript when we need or want to. One thing to bear in mind if you are advertising via JavaScript is that you can use NoFollow on JavaScript links.
Eric Enge: If people do have ads on your site, it's still Google's wish that people NoFollow those links, correct?
Matt Cutts: Yes, absolutely. Our philosophy has not changed, and I don't expect it to change. If you are buying an ad, that's great for users, but we don't want advertisements to affect search engine rankings. For example, if your link goes to a redirect, that redirect could be blocked from robots.txt, which would make sure that we wouldn't follow that link. If you are using JavaScript, you can do a NoFollow within the JavaScript. Many, many ads use 302s, specifically because they are temporary. These ads are not meant to be permanent, so we try to process those appropriately.
Our stance has not changed on that, and in fact we might put out a call for people to report more about link spam in the coming months. We have some new tools and technology coming online with ways to tackle that. We might put out a call for some feedback on different types of link spam sometime down the road.
Eric Enge: So what if you have someone who uses a 302 on a link in an ad?
Matt Cutts: They should be fine. We typically would be able to process that and realize that it's an ad. We do a lot of stuff to try to detect ads and make sure that they don't unduly affect search engines as we are processing them.
The nice thing is that the vast majority of ad networks seem to have many different types of protection. The most common is to have a 302 redirect go through something that's blocked by robots.txt, because people typically don't want a bot trying to follow an ad, as it will certainly not convert since the bots have poor credit ratings or aren't even approved to have a credit card. You don't want it to mess with your analytics anyway.
Eric Enge: In that scenario, does the link consume link juice?
Matt Cutts: I have to go and check on that; I haven't talked to the crawling and indexing team specifically about that. That’s the sort of thing where typically the vast majority of your content is HTML, and you might have a very small amount of ad content, so it typically wouldn't be a large factor at all anyway.
Eric Enge: Thanks Matt!
Matt Cutts: Thank you Eric!






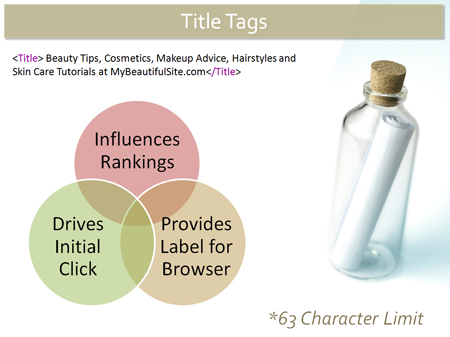
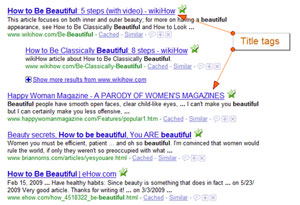 But what about the visitor? What does the searcher see? Let say a searcher types "how to be beautiful" into the search engine and two results are displayed. One reads "How to Look Good and Feel Great" and another reads "How to Look Beautiful Even When you Don't Feel Like It." Which of these two is more likely to be clicked by the visitor?
But what about the visitor? What does the searcher see? Let say a searcher types "how to be beautiful" into the search engine and two results are displayed. One reads "How to Look Good and Feel Great" and another reads "How to Look Beautiful Even When you Don't Feel Like It." Which of these two is more likely to be clicked by the visitor?  Implementing your title tags properly is crucial to ensuring they are effective. There are a number of easy mistakes that you can make if you don't take the time to do it right. It's easy to want to blast through your title tags, especially if you have a lot of pages. But because the title tag is so important, you want to take care in developing them properly. Here are a few common issues:
Implementing your title tags properly is crucial to ensuring they are effective. There are a number of easy mistakes that you can make if you don't take the time to do it right. It's easy to want to blast through your title tags, especially if you have a lot of pages. But because the title tag is so important, you want to take care in developing them properly. Here are a few common issues: So let's address using your business name in your title tags. As I said earlier, sometimes its wise but that shouldn't be the default position.
So let's address using your business name in your title tags. As I said earlier, sometimes its wise but that shouldn't be the default position.


